A requirement is a condition or capability to which the system must conform. Requirements are things, to which the system being built must conform, and conformance to some set of requirements defines the success or failure of projects. It makes sense to find out what the requirements are, write them down, organize them, and track them in the event they change.
This white paper concentrates on, problems of requirements management, an overview of RequisitePro, and how can we achieve traceability between Requirements Specification Document and Use Cases Specification Document.
2. Requirements Management
Requirements management is a systematic approach to finding, organizing, and documenting and tracking the changing requirements of a system.
Requirements management is a systematic approach to finding, organizing, and documenting and tracking the changing requirements of a system.
2.1. The Problems of Requirements Management
Requirements do change. In fact, some requirement change is desirable. A changed requirement means that more or less time has to be spent on implementing a particular feature, and a change to one requirement may affect other requirements.
Managing requirement change includes activities such as establishing a baseline, keeping track of the history of each requirement, determining which dependencies are important to trace, establishing traceable relationships between related items, and maintaining version control.
3. RequisitePro for managing requirements
RequisitePro is a CASE tool from Rational that supports team-work based requirements management. RequisitePro automates management of requirements traceability. RequisitePro is integrated with Microsoft Word to capture requirements documents.
RequisitePro helps projects succeed by giving teams the ability to manage all project requirements comprehensively and facilitating team collaboration and communication.
RequisitePro lets you organize, prioritize, trace relationships, and easily track changes to your requirements very affectively. The program’s unique architecture and dynamic links make it possible for you to move easily between the requirements in the database and their presentation in Word documents. For each requirement a change history is maintained, capturing the who, what, when, and why of the change.
RequisitePro is a CASE tool from Rational that supports team-work based requirements management. RequisitePro automates management of requirements traceability. RequisitePro is integrated with Microsoft Word to capture requirements documents.
RequisitePro helps projects succeed by giving teams the ability to manage all project requirements comprehensively and facilitating team collaboration and communication.
RequisitePro lets you organize, prioritize, trace relationships, and easily track changes to your requirements very affectively. The program’s unique architecture and dynamic links make it possible for you to move easily between the requirements in the database and their presentation in Word documents. For each requirement a change history is maintained, capturing the who, what, when, and why of the change.
3.1. Requirements
RequisitePro organizes requirements and provides traceability and change management throughout the project lifecycle. Requirements can be created in a document. All requirements information is stored in the database.
3.2. Requirement Type
A requirement type is an outline for your requirements. Requirement types are used to classify similar requirements so they can be efficiently managed. We can create user defined requirement types that are appropriate for our project.
You can assign attributes to these Requirement types also. Each type of requirement has attributes, and each individual requirement has different attribute values. For example, requirements may be assigned priorities, identified by source and rationale, delegated to specific sub-teams within a functional area, given a degree-of-difficulty designation, or associated with a particular iteration of the system.
3.3. Requirement Attributes
In RequisitePro, requirements are classified by their type and their attributes. An attribute provides information to manage a requirement. Attributes can provide crucial information to help a team plan, communicate, and monitor project activities from the analysis and design phases through the release phase.
Attribute information may include the following:
1. The relative benefit of the requirement
2. The cost of implementing the requirement
3. The priority of the requirement
4. The difficulty or risk associated with the requirement
5. The relationship of the requirement to another requirement
In Figure 3-2, feature requirements are displayed for a specific project in RequisitePro. Requirements contain a name and text, and they can be qualified with attributes to provide specific details. Note that even without displaying the entire text for each requirement, we can learn a great deal about each requirement from its attribute values. A requirements priority and difficulty (which may be assigned by different team members) will help the team begin to scope the project to available resources and time, taking into account both stakeholder priorities and a very rough estimate of effort reflected in the difficulty attribute value. In more detailed types of requirements, the priority and effort attributes may have more specific values (for example, estimated time, lines of code) with which to further refine scope. This multidimensional aspect of a requirement, compounded by different types of requirements—each with its own attributes—is essential to organizing large numbers of requirements and to managing the overall scope of the project.
You can use attributes to determine which requirements to implement in the next release. For example, you may decide that in the first release, you will implement only those requirements evaluated as high risk, with high difficulty. If you have assigned risk and difficulty attribute values to each requirement, you can then easily query all requirements of high risk and high difficulty.
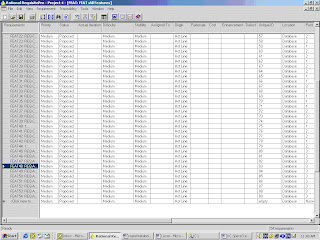
Figure 3‑2: Attribute Matrix for Feature Requirements
3.4. Project
A RequisitePro project includes a requirements database and its related documents. We can define project structure and sets up security permissions for the project’s users to view and update.
In RequisitePro, requirements are classified by their type and their attributes. An attribute provides information to manage a requirement. Attributes can provide crucial information to help a team plan, communicate, and monitor project activities from the analysis and design phases through the release phase.
Attribute information may include the following:
1. The relative benefit of the requirement
2. The cost of implementing the requirement
3. The priority of the requirement
4. The difficulty or risk associated with the requirement
5. The relationship of the requirement to another requirement
In Figure 3-2, feature requirements are displayed for a specific project in RequisitePro. Requirements contain a name and text, and they can be qualified with attributes to provide specific details. Note that even without displaying the entire text for each requirement, we can learn a great deal about each requirement from its attribute values. A requirements priority and difficulty (which may be assigned by different team members) will help the team begin to scope the project to available resources and time, taking into account both stakeholder priorities and a very rough estimate of effort reflected in the difficulty attribute value. In more detailed types of requirements, the priority and effort attributes may have more specific values (for example, estimated time, lines of code) with which to further refine scope. This multidimensional aspect of a requirement, compounded by different types of requirements—each with its own attributes—is essential to organizing large numbers of requirements and to managing the overall scope of the project.
You can use attributes to determine which requirements to implement in the next release. For example, you may decide that in the first release, you will implement only those requirements evaluated as high risk, with high difficulty. If you have assigned risk and difficulty attribute values to each requirement, you can then easily query all requirements of high risk and high difficulty.

Figure 3‑2: Attribute Matrix for Feature Requirements
3.4. Project
A RequisitePro project includes a requirements database and its related documents. We can define project structure and sets up security permissions for the project’s users to view and update.
3.5. Project Database
The project database is the requirements database managed by RequisitePro. When you use RequisitePro, you can use one of three physical databases to store requirements: Microsoft Access, Oracle, or Microsoft SQL Server. Each RequisitePro project has its own database, where all the requirements for a project are stored. (With the exception of Microsoft Access, all of these databases may contain more than one project.)
In the project database, requirements can be added, modified, or deleted. When requirements are changed in a document, the changes are updated in the database. Often a project includes a variety of requirements documents, such as a product requirements document, a system requirements document, software and hardware specifications, user requirements, quality assurance procedures, and test plans. Information from all project documents is stored in the project database. The database centralizes information, so that members of the project team can update requirements, manage priorities and test plans, and report the project’s progress in one shared repository.
3.6. Project Version Control
RequisitePro’s version control lets you trace change by archiving projects. You can manage multiple versions of your projects, retrieving, modifying, and returning revisions to the archive in an organized and consistent manner.
3.7. Project List
A RequisitePro project list is a personal library of accessible RequisitePro projects. Each user’s list is unique.
3.8. Explorer
The Explorer is RequisitePro’s primary navigation window. You can use the Explorer to view your project structure and artifacts and to work with project information. The Explorer reflects saved changes made to an open document, view, or requirement.
3.9. Views
RequisitePro views are windows to the database. Views present information about a project, a document, or requirements graphically in a table (matrix) or in an outline tree. Requirements, their attributes, and their relationships to each other are displayed and managed in views. RequisitePro includes query functions for filtering and sorting the requirements and their attributes in views.
Three kinds of views can be created:
1. The Attribute Matrix displays all requirements of a specified type. The requirements are listed in the rows, and their attributes appear in the columns.
2. The Traceability Matrix displays the relationships (traceability) between two types of requirements.
3. The Traceability Tree displays the chain of traceability to or from requirements of a specified type.
3.10. Documents
A requirements document is a specification that captures requirements, describes the objectives and goals of the project, and communicates product development efforts.
Each requirements document belongs to a particular document type. RequisitePro manages requirements directly in the project documents. When you build a requirements document, RequisitePro dynamically links it to a database, which allows rapid updating of information between documents and views. When you save revisions, they are available to team members and others involved with the project.
3.11. Document Type
A document type identifies the type of document, such as a use-case or a software requirements specification, and helps ensure consistency across documents of the same type. A document type is an outline that is applied to documents. The outline can include the default font for the document, the available heading and paragraph styles, and the default type of requirements for the document, or it can encompass both formatting conventions and an outline that helps you organize your requirements information
3.12. Hierarchical Relationships
Hierarchical requirement relationships are one-to-one or one-to-many, parent-child relationships between requirements of the same type. Use hierarchical relationships to subdivide a general requirement into more explicit requirements. Each child requirement can only have one parent, but a requirement can be both a parent and a child. The parent and child requirements must be located in the same place. If a parent requirement appears in a document, the child requirement should also appear in that document.
Hierarchical requirement relationships are one-to-one or one-to-many, parent-child relationships between requirements of the same type. Use hierarchical relationships to subdivide a general requirement into more explicit requirements. Each child requirement can only have one parent, but a requirement can be both a parent and a child. The parent and child requirements must be located in the same place. If a parent requirement appears in a document, the child requirement should also appear in that document.
3.13. Traceability Relationships
Traceability links requirements to related requirements of same or different types. RequisitePro’s traceability feature makes it easy to track changes to a requirement throughout the development cycle. Without traceability, each change would require a review of your documents to determine which, if any, elements need updating.
When working with traceability relationships:
1. You can create a traceability relationship between requirements of the same or different types.
2. You can create traceability relationships between requirements that exist in the same document, in different documents, or in the project database.
3. You can create, view, and manipulate traceability relationships in a document or in a view.
4. Traceability relationships are a type of change-managed relationship in RequisitePro. If either end-point of the connection is changed, the relationship becomes suspect. If you modify the text or selected attributes of a requirement that is traced to or traced from another requirement, RequisitePro marks the relationship between the two requirements “suspect.”
5. Traceability relationships cannot have circular references. For instance, a traceability relationship cannot exist between a requirement and itself, nor can a relationship indirectly lead back to a previously traced from node. RequisitePro runs a check for circular references each time you establish a traceability relationship.
Traceability links requirements to related requirements of same or different types. RequisitePro’s traceability feature makes it easy to track changes to a requirement throughout the development cycle. Without traceability, each change would require a review of your documents to determine which, if any, elements need updating.
When working with traceability relationships:
1. You can create a traceability relationship between requirements of the same or different types.
2. You can create traceability relationships between requirements that exist in the same document, in different documents, or in the project database.
3. You can create, view, and manipulate traceability relationships in a document or in a view.
4. Traceability relationships are a type of change-managed relationship in RequisitePro. If either end-point of the connection is changed, the relationship becomes suspect. If you modify the text or selected attributes of a requirement that is traced to or traced from another requirement, RequisitePro marks the relationship between the two requirements “suspect.”
5. Traceability relationships cannot have circular references. For instance, a traceability relationship cannot exist between a requirement and itself, nor can a relationship indirectly lead back to a previously traced from node. RequisitePro runs a check for circular references each time you establish a traceability relationship.
3.14. Traced to/Traced from Relationships
The trace to/trace from state represents a bidirectional dependency relationship between two requirements. The trace to/trace from state is displayed in a Traceability Matrix or Traceability Tree when you create a relationship between two requirements. For example, you might create a feature requirement (Requirement A) that calls for a new command to be added to a particular menu in your application. In addition, in another requirements document, you might create a use-case requirement (Requirement B) associated with that menu item. You would thus create a traceability relationship in which the use-case requirement (B) is traced from the feature requirement (A).
There can be only one traceability relationship between any two requirements. The difference between a trace to and a trace from relationship is perspective. In the example above, both of the following statements are true:
1. A is traced to B
2. B is traced from A
3.15. Direct and Indirect Traceability Relationships
Traceability relationships may be either direct or indirect.
In a direct traceability relationship, a requirement is physically traced to or from another requirement. For example, if Requirement A is traced to Requirement B, and Requirement B is traced to Requirement C, then the relationships between Requirements A and B and between Requirements B and C are direct relationships. The relationship between Requirements A and C is indirect. Indirect relationships are maintained by RequisitePro; you cannot modify them directly.
Direct and indirect traceability relationships are depicted with arrows in traceability views. Direct relationships are presented as solid arrows, and indirect relationships are dotted and lighter in color.
3.16. Suspect Relationships
A hierarchical relationship or a traceability relationship between requirements becomes suspect if RequisitePro detects that a requirement has been modified. If a requirement is modified, all its immediate children and all direct relationships traced to and from it are suspect. When you make a change to a requirement, the suspect state is displayed in a Traceability Matrix or a Traceability Tree. Changes include modifications to the requirement name, requirement text, requirement type, or attributes.
4. Traceability with Use Cases
Use case documents in RequisitePro contain use-case textual descriptions. Requirements in these documents are linked to a database that stores additional requirement information, such as attributes, traceability links, versioning, change history, project security and more. From the RequisitePro database, you can query the requirement information to check coverage and measure the impact of change.
1. Requirement text is clearly marked.Requirement text is visually differentiated from additional descriptive information in the document (See Figure 4-1).
2. Any modification to use case documents is automatically tracked.Information about who modifies what, when, and why is stored in the Rational RequisitePro database. These revisions help you gain control of use case changes. Requirements Specification documents can be linked to use case documents they may relate to.
By tracing use cases to business requirements , feature-level requirements , tests, or even other use cases you can more easily measure the impact of change on related requirements and verify coverage.
As we have attributes matrix for Requirement Specification, it will be same for Use Case Specification document also. These make the process of deciding the use cases to implement in a particular release more objective.
Traceability helps measure the impact of change and ensures requirements coverage. For instance, if a business needs changes, what use cases might be impacted? By establishing traceability links, you can query the requirements to know whether all business needs are implemented at use case level.
Revisions help you track who changes what, when and why, to provide an audit trail of requirement changes. This helps you measure the stability of requirements and concentrate on more stable requirements first, inherently diminishing the amount of change.
Note that you can change the out-of-the-box use case attributes and their values in the RequisitePro project associated with your model.
Benefits of Managing Use CasesYou can use all RequisitePro capabilities to sort your use cases (by priority, by iteration number, etc.), to query on specific use cases (only the use cases planned for the next iteration), and even produce requirements metrics.
Using an Attribute Matrix View in Rational RequisitePro (see Figure 3-2), you can view all or a select subset of use cases and their respective attributes. This helps you organize the use case information. You can run queries to determine which use cases are assigned to which designer, how difficult they are to implement, or which requirements are not covered in use case.
Once you have selected the use cases to be implemented in the next iteration, you should verify that requirements are traced from use cases ensuring that all the functionality will be tested. The Traceability Matrix View in Figure 4-4 shows the relationships established between use cases and requirement specification document. A suspect link (red slashed arrow in Figure 4-4) indicates that requirement needs to be revisited due to a change. By querying on suspect links, you will know which requirements have changed, and is there any change in use case.

Figure 4‑4: Traceability between Feature Type and Use case Type Requirements
5. Summary
By managing requirements in conjunction with other requirement types your project can be better scope managed, change can be controlled and coverage can be verified. In short, RequisitePro helps ensure that you are implementing the functionality that was agreed upon, and that this functionality will be fully tested.
6. References
· Rational Library - http://www-106.ibm.com/developerworks/rational/library/content/RationalEdge/archives/requirements.html
· User Guide to RequisitePro by Rational - http://www.se.fh-heilbronn.de/usefulstuff/Rational%20Rose%202003%20Documentation/reqpro_user.pdf
